Warren G. Abrahamson1 & Michael R. Weaver2
1Department of Biology and 2Department of Information Services & Resources
Bucknell University, Lewisburg, PA 17837
Introduction
This week’s exercise explores the fundamentals of sampling theory using virtual forests. Two Pennsylvania old-growth forests were digitized enabling you to employ haphazard, systematic, and random sampling methods while investigating sampling protocols based on sampling areas versus distances. As you sample these virtual forests, you will discover that the efficiencies of sampling methods vary for different types of natural communities and that species differ in spatial distribution. Finally, you will determine the species diversity of both virtual forests and will make predictions about their successional trends. The obvious advantage of this simulation model is that you can quickly sample a forest community using different sampling criteria and methodologies.
Objectives
- To help you understand sampling theory.
- To demonstrate the importance of avoiding bias so that a sample is obtained that accurately estimates species occurrences.
- To compare area versus distance-sampling methods and their relative efficiencies.
- To learn about the measurement of abundance, dispersion, and community structure.
- To help you understand ecological succession.
Basic concepts
- A community is an assemblage of interacting populations of species that occupy a given area.
- A community is characterized by both a physical and biological structure.
- The mix of species that makes up a community defines its biological structure.
- Population interactions such as competition, predation, parasitism, and mutualism influence community organization.
- The biological structure of a community can be defined, in part, by the density, frequency, dominance, and importance of each of the species that compose the community.
- Spatial variation in community structure.
- Succession and replacement of species over time.
Background
Ecologists and conservation biologists frequently need to know how a community of organisms is structured. That is, what species compose the community; how abundant is each species; how do the species interact; and are some species increasing in abundance while others are decreasing in abundance over time? Such information is invaluable when biologists develop conservation plans for natural areas or recovery plans for threatened or endangered species. Furthermore, measures of species abundances within a community taken at one point in time provide a baseline against which future measures of species abundances within that community can be compared. Such timelines of community data allow ecologists to measure species changes within communities and to better understand succession within a given natural community or the impacts of specific land-management plans.
The need to assess community structure has generated a number of quantitative field methods as well as an appreciation of which methodology works best in a given situation. These methods are designed to generate reliable estimates of the abundance and distribution of each species within a community. Such data make it possible to compare species or groups of species within a community or to contrast species composition and abundance among communities.
Why Sample?
Sampling methods are invaluable for numerous biological investigations. Such methods are used to determine the efficacy of new medicines, the responses of cells to various treatments, and the structure of a natural community. It would be extremely time consuming, for example, to count and measure every individual of each species within a community in order to determine the abundances and distributions of each species within the community. Sampling methods enable us to estimate reliable information by use of samples. However, it is critical that the samples be taken without bias and in sufficiently large number so that the resulting data can be summarized to give valid estimates of the desired parameters.
Sampling Methods
The specific sampling method used to assess community structure depends on the nature of the organisms and the community to be sampled. For example, we would use “mark and recapture” or “capture per unit effort” methods to determine abundance estimates for mobile or secretive animals (e.g., deer, mice), whereas we would employ area, distance, or line-transect methods for sessile or sedentary animals (e.g., corals) and for plant communities (e.g., forest trees).
In this exercise, you will investigate the application of two quantitative field methods best suited to study communities of sessile or sedentary animals and most types of vegetation: (1) the area-sample method and (2) the distance-sample method. As you apply these two methods to simulated forest communities, you will become familiar with the subtleties of each method and will come to understand when one or the other method would be best used. Because you will sample known forest communities, you will compare your abundance estimates against actual abundance values for each tree species. As a consequence, you will use the degree of deviation of your estimates to compare sampling methods and to determine the reliability of your estimates for common species versus rare species.
When using area samples, ecologists must determine the appropriate quadrat size to use on the basis of the size and density of the individuals within the community being sampled. Quadrats must be large enough to contain a number of individuals, but small enough that the individuals present can be separated, counted, and measured. For example, quadrat sizes for herbaceous vegetation might be 1 m2, while for shrubs 10-20 m2, and 100 m2 for forest trees.
Quadrat shape is also important as it affects the ease of establishing quadrats and the efficiency of sampling. For example, circular ‘quadrats’ are more easily established than square quadrats; and elongated rectangular ‘quadrats’ furnish more variety of species than an equal number of square quadrats of the same area. This latter relationship holds because a rectangle encompasses more environmental variety due to environmental gradients (e.g., slopes, soil-moisture variation) than a square of the same area. However, because rectangular quadrats have more perimeter than square quadrats of the same area, accuracy tends to decline as quadrats become more elongated due to edge effect (Barbour et al. 1999). The best quadrat size and shape depends on the application. In our exercise, we will use square quadrats.
Where to Sample
Three approaches could be used to sample within communities of organisms but as you will learn, these approaches are not equal in their ability to generate reliable estimates of species abundance. (1) Haphazard or convenience sampling selects samples that are readily available – such samples are almost never random samples. The extent to which community statistics generated from such sampling can be generalized to the community as a whole depends on the degree to which the samples represent the whole. The more homogeneous the community from which our samples are drawn, the more likely haphazard sampling will reliably represent the community. However, the more heterogeneous the community, the more likely such sampling will offer a biased, unrepresentative estimates. In contrast, (2) random sampling ensures that all individuals within a community have an equal chance of being sampled. While this approach is likely to generate reliable estimates of community parameters with sufficient sampling, random sampling can be difficult under field conditions. It could require, for example, that each individual or area within a community be assigned a number and that the numbers to be sampled be selected by a truly random process. A variation of random sampling, referred to as stratified-random sampling, subdivides the community into any number of homogeneous regions, each of which is then randomly sampled. Under field conditions, (3) replicated systematic sampling is often applied because it avoids bias better than haphazard sampling and it is easier to apply than random sampling. With systematic sampling the procedure selects, for example, every 30th individual or perhaps areas to be sampled every 30 meters along equidistant transect lines placed across the sampled community. Systematic sampling is not equivalent to random sampling, however, for if there is periodic ordering within the chosen samples systematic sampling may have a larger error than a random sample.
Measures of Species Abundance – Density, Frequency, Dominance, and Importance
Several standard measures of absolute and relative abundance are used to assess the contribution of each species to a community (Barbour et al. 1999). These measures include: density, the number of individuals within a chosen area (e.g., m2, hectare); relative density, the density of one species as a percentage of total density; frequency, the percentage of total quadrats or points that contains at least one individual of a given species; relative frequency, the frequency of one species as a percentage of total frequency; dominance, the total basal area of a given species per unit area within the community; relative dominance, the dominance of one species as a percentage of total dominance; and importance, expressed as the relative contribution of a species to the entire community expressed as a combination of relative density, relative frequency, and relative dominance (see the Appendix for mathematical definitions of each measure).
Think carefully about the meaning of each of these measures – each offers a different insight into the abundance of the species composing a community. Saplings, for example, typically have a much higher density but much lower dominance than mature trees. Density tells us the number of individuals per unit area but density is not necessarily proportional to dominance because dominance for a given species expresses the area occupied by the species per unit area (e.g., per m2). A species composed of primarily large individuals can have high dominance but it will likely have low density, and unless regularly distributed, it will also have low frequency. Frequency, which is often independent of density, expresses one measure of the distribution of individuals within the community. A clumped species can have high density but also low frequency because it occurs in a limited portion of the community. In contrast, a species that is individually and regularly distributed over the landscape will have a high frequency but can have low density. Relative importance, as a combination of relative values for density, frequency, and dominance, is used as a summary of the influence that an individual species may have within the community. Recognize that two species with the same relative importance can have markedly different values for relative density, frequency, or dominance as any differences can be overshadowed by the addition process (Barbour et al. 1999).
Measures of Distribution
Individuals of a species can be randomly distributed across a community (i.e., the location of one individual of a given species has no relationship with the location of other individuals of that species). Individuals of other species might be singly and regularly distributed through out the community (an extreme example is the uniform spacing of orchard trees), while the individuals of still other species could be clumped (i.e., the presence of one individual of a given species increases the probability of finding another individual of that species nearby). Thus, ecologists recognize three primary patterns of distribution: (1) random, (2) regular (uniform) or hyperdispersed, and (3) clumped (aggregated) or underdispersed (Barbour et al. 1999).
There are a number of reasons why plants show clumped distributions. Many plants are highly clonal (i.e., they can propagate by vegetative means as do goldenrods and aspens) so once a seedling establishes at a given site, the plant spreads to produce numerous, spatially separated (but genetically identical), aboveground stems. In addition, environmental gradients are common in nature so that a site that is good for one individual of a given species is likely to be good for other individuals of that species. Yet there are forces in nature that counteract clumping. Competition among individuals for water in deserts or light in forests can favor regular spacing. Similarly plants that are clumped are more likely to be found by their herbivores or pathogens (Barbour et al. 1999).
Measures of Richness, Evenness, and (Species) Diversity
Species richness [the number of species occurring within a specific area or community], species evenness or equitability [the distribution of individuals among species], and species diversity [typically measured as a combination of species richness and species evenness; that is, species richness weighted by species evenness, see Appendix] are measures unique to the community level of ecological organization (Barbour et al. 1999). These statistics reflect the biological structure of a community. A community with high species richness and diversity, for example, will likely have a complex network of trophic pathways. In contrast, a community with low species richness and diversity will likely have fewer species and trophic interactions. Interactions among species (e.g., energy transfer, predation, competition) within the food webs of communities with high species diversity are theoretically more complex and varied than in communities of low species diversity. Indices of species richness and species diversity are often used in a comparative manner, that is, to compare communities growing under different environmental conditions or to contrast seral stages of a succession.
Information about Communities
Mohn Mill Natural Area –
The 154-ha Mohn Mill area (N41°4’, W77°8’) straddles the boundary of Union and Lycoming Counties at their intersection with Clinton County. Elevations in the Mohn Mill area range from approximately 420 to 570 m above mean sea level with bottomlands and gently sloping to steep slopes. The sandstone-derived soils include loams, sandy loams, and stony to very stony loams.
The Mohn Mill area has experienced many natural disturbances during recent decades including canopy-damaging windstorms as well as ice and wet snow events (W. G. Abrahamson personal observation). In addition, chestnut blight occurred in the region during the 1930’s, eliminating chestnut from forest canopy. Gypsy moth outbreaks occurred within the Mohn Mill site from 1979 to 1982 and again during of 1996. The site was logged approximately 100 years ago between 1904 and 1912 during the period identified as the “clear-cut or hemlock-chemical wood” era (Abrams and Ruffner 1995). Currently, there is evidence of considerable browsing by white-tailed deer, which likely inhibits the regeneration of oaks.
The Mohn Mill area is a Pennsylvania Department of Conservation and Natural Resources (DCNR) proposed wild-plant sanctuary primarily because of the presence of the federally endangered northeastern bulrush (Scirpus ancistrochaetus Schuyler). The small, seasonal ponds that harbor the northeastern bulrush occur within an oak-canopied forest matrix that is likely crucial to the long-term survival of this plant. Although the Mohn Mill site is protected from logging, a recent study of the successional trends at Mohn Mill showed that the site is experiencing a replacement of oaks by more shade-tolerant red maple (Abrahamson and Gohn 2004). Click here for a copy of the Abrahamson and Gohn publication.
Snyder-Middleswarth
State Park Natural Area –
The 200-ha Snyder-Middleswarth Natural Area (N40°48’, W77°19’), located in Snyder County, includes one of the few stands of old-growth hemlock-yellow birch forest remaining in Pennsylvania and is among the largest such stands existing within Pennsylvania state forests. Thanks originally to inaccessibility and in 1965 to its preservation as a National Natural Landmark, a 135-ha portion of this forest has never been logged. Old-growth forests have become increasingly rare in North America since the time of European colonization and are particularly rare in central Pennsylvania because of intensive logging for timber and charcoal production during the past 150 years. As a consequence, eastern old-growth forest exist in small stands that are isolated from other old-growth forests by an intervening matrix of successional forests.
The Snyder-Middleswarth old-growth forest is located in a narrow and steep ravine between two east and west-running ridges; Buck Mountain lies to the north and Thick Mountain to the south. The ravine, created by Swift Run, has well-developed north-facing and south-facing slopes as well as a bottomland. Elevations in the area range from 450 m to 550 m, with slopes varying in steepness from 1-68%. The predominant soils are extremely stony and sandy well-drained loams that have weathered from sandstone and shale. As a consequence, these soils have low to moderate available water capacity and have little pH buffering capacity.
There are recurrent natural disturbances within this forest. Windstorms, especially those associated with snow or ice events, have toppled a number of the larger hemlock and yellow birch during the past three decades (W. G. Abrahamson, personal observation). The crowns of slope and ridge top trees frequently show evidence of wind and/or ice damage.
Humans are also having impacts on the old-growth forest. Acid precipitation has seriously impacted the area by enhancing the acidity of soils and of Swift Run. The water that enters Swift Run moves through Tuscarora sandstone and soils derived from this hard sandstone. Because these substrates are unable to buffer the strongly acidic precipitation, the portion of Swift Run within the old-growth forest area has a pH too low for fish (e.g., native brook trout) to survive (low pH releases aluminum, which in turn is toxic to fish and other aquatic organisms). The unnamed creek that joins Swift Run near the parking area has a substantially higher pH because its waters percolate through Juniata sandstone and its derived soil, which has greater buffering ability. As a result, fish such a brook trout do occur as far upstream as the confluence of these creeks.
Humans have introduced several herbivorous insects to North America that threaten the stability of the Snyder-Middleswarth Natural Area. The continued domination of the old-growth forest by hemlock could be appreciably impacted by the hemlock woolly adelgid. This exotic herbivore was first reported in southeastern Pennsylvania in the late 1960s and it has been observed in the Snyder-Middleswarth old-growth forest since 2003 (W. G. Abrahamson personal observation). Gypsy moth outbreaks have occurred periodically within central Pennsylvania since the mid-1970s and have impacted the oak canopies of the south-facing and ridge tops during multiple growing seasons. There is evidence of browsing by white-tailed deer, which likely inhibits regeneration. A recent study of the Snyder-Middleswarth Natural Area detailed the patterns of vegetation and succession within the site (Zawadzkas and Abrahamson 2003). Click here for a copy of the Zawadzkas and Abrahamson publication.
Assignments
We will examine a number of questions in the following exercises using a computer simulation model, EcoSampler, to sample these two communities. EcoSampler can be accessed using a Windows-platform computer running Internet Explorer or Mozilla, or a Macintosh computer running Safari or Internet Explorer.
Assignment 1 – Haphazard, Random, and Systematic Sampling –This assignment will investigate the differences among haphazard, random, and systematic sampling. Click ‘Begin.’
- Next select the ‘Mohn Mill Natural Area’ and then click on ‘description’ to obtain background on the Mohn Mill site as well as information about the size of quadrat used when the area-sampling method is selected.
Next decide on the sampling method to use (i.e., area or distance) as well as how to draw samples with this method – under ‘area,’ select ‘haphazard.’ The window that opens shows the entire virtual forest community (‘community view’). The dots scattered across the window are the locations of individual forest trees. Near the upper right corner of the ‘community view’ window, you will see ‘Topographical View’ – clicking this link produces a three-dimensional topographic image of the Mohn Mill Natural Area.
- You can control the display of actual values, color-coding, and creating links for randomly selected quadrats by using the ‘Configuration options’ near the bottom of the ‘select a forest’ window and ‘community view’ window. Leave all configuration options at their default values for now.
- Begin sampling by moving the cursor to a location within the community. When you click the mouse you will place a quadrat at this location and a new window will appear showing the identities and relative sizes of all individuals within the quadrat (‘quadrat view’). The numbers adjacent to the symbols show the tree’s basal diameter, a necessary datum to calculate dominance.
- A pop-up window will appear with the message ‘New Species Found’ and a list of each newly sampled species. Click ‘OK’ and then click on the name of each species labeled ‘(new)’ in the legend to read about its natural history and see several images. Click on the underlying ‘Quadrat View’ window or click on ‘Close Window.’
- If you are satisfied with your choice of quadrat location, click ‘Sample this quadrat.’ You will return to ‘community view’ and can select another quadrat location.
- In the right margin of the ‘community view’ window, EcoSampler generates a record of the number of plants (i.e., individuals) sampled; the number of species sampled, and coordinates of sampled quadrats.
- “How do I know when a sufficient number of quadrats are sampled?” You will see a graph of the cumulative number of species sampled on the Y axis versus the number of quadrats sampled (and hence the amount of area sampled) on the X axis in the bottom portion of the ‘community view’ window. Field biologists use ‘species-area’ graphs as a semi-objective means to determine when the community is sufficiently sampled. ‘Species-area’ curves rise sharply at first as each newly sampled quadrat reveals species not previously sampled. But the curve levels off sooner or later depending on the species richness of the community [species richness is the number of unique species within a community] because additional sampling encounters only individuals of previously sampled species.
|
|
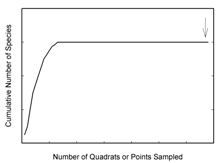 |
- The most common species can be sufficiently sampled to calculate reliable abundance estimates after only 25 to 30 quadrats are sampled depending on the species richness of the community. However, gathering enough data on rare species can require a lot more sampling. Use the ‘species-area’ graph to track your progress finding species. While this graph does not illustrate the numbers of sampled individuals of any species (you will see this information once you calculate abundance results in the next step), it does provide insight into the success of finding species within the community. The best approach is to continue sampling until you are well out on the curve’s asymptote (at the arrow in the figure above). The more sampling you do, the more likely your estimates will reliably reflect the community’s actual values. A field biologist has to weigh the advantages of additional sampling against the time and cost expended for what can be small gains in accuracy.
- After you feel that you have sampled adequately, calculate the abundance estimates by clicking ‘Perform Calculations.’ A new window will appear containing a vertical list of species on the left-hand side and the various abundance measures listed across the top. The black numbers are calculated from your sampling and the pink numbers are the actual values. If you need to augment your sample, click ‘Continue Sampling.’ If you are satisfied with your sampling, click ‘Finish.’ Keep in mind, however, that under field conditions, we would not know the actual values.
- Near the bottom of this output table are ‘Estimates of time commitment.’ This estimate, which is based on the average time involved in establishing and sampling a quadrat or point as well as the travel time between quadrats or points, provides an estimate of the time expended to sample the number of quadrats or points sampled under field conditions. Consider the tradeoff between the accuracy of your sampling and time and cost expended.
- Once you click ‘Finish,’ a new window will appear with a summary of the calculated values as well as histograms that show the tree-size distributions for each species sampled. Save a copy of this window to refer to for your write up by right clicking the mouse on PCs or holding down the control key and clicking the mouse on Macs and select Print. Next, click on the Preferences button and select Landscape orientation. Finally, chose Adobe pdf under Select printer – doing so will allow you to save the window to your server space.
- Next, repeat the exercise using random sampling by clicking ‘Use another sampling technique with this community .’ Then click, ‘random or systematic.’ Next click, ‘Generate a random list of 50 quadrats.’
- Repeat the procedure used above, only this time, use the randomly generated list of X and Y coordinates to identify the quadrats to sample. With this approach, every quadrat has the same probability of selection thereby eliminating any investigator bias to sample in one area over another. Again, use the ‘species-area’ curve to determine when sufficient sampling has been accomplished. Calculate your estimates of species abundance and save a copy for reference in preparing your write up.
- Finally, repeat the exercise using systematic sampling. To do, click ‘Use another sampling technique with this community.’ Then click, ‘random or systematic.’ But this time, instead of using the random list of quadrats to determine which quadrat to sample, divide the total number of quadrats in the community by the number of quadrats of that you think you will need to sample. For example, if the forest is of size that would contain 300 quadrats (a grid of 20 X 15 quadrats) and if we assume that you will need to sample 50 quadrats in order to calculate reliable abundance estimates, you would sample every 6th quadrat (i.e., 300/50 = 6). Begin at some point within the forest and sample that quadrat and every 6th quadrat until you accumulate a sufficiently robust sample. Calculate your estimates as before and save a copy of your results to refer to in preparing your write up.
Questions to Discuss in Your Write Up of Assignment 1
- Examine the reliabilities of haphazard, random, and systematic sampling by comparing the actual occurrence values to your estimated values. How might haphazard sampling introduce bias into the choice of which individuals are sampled?
- Compare the efficiency of random and systematic sampling by reflecting on their use in the field (use the estimates of time commitment for each sampling). What advantage or disadvantage might either method hold under field conditions? Hint: consider how the steps you used for random versus systematic sampling would work under field conditions.
- Using the output from random sampling, which species is the most common and which species is the rarest among those sampled (use the actual importance values to determine this)? Compare the accuracy of your abundance estimates for the most common species against the actual values. Next compare your abundance estimates for the rarest species against the actual values. Test the accuracy of your estimates by determining the percentage error of your calculated value versus the actual value. (e.g., red maple density actual = 403.7 versus 400 calculated represents a 0.9% difference, while white ash density actual = 0.8 versus 0.4 calculated is a 50% difference). Based on these percentage errors, is your estimate for the rarest species as reliable as that for the most common species? Why or why not?
- Identify the species with the highest density value. Describe the structure of its population by examining its density, dominance, and frequency values. For example, the population of this species may be composed of numerous, relatively small stems that are widely distributed across the sampled area. Next, examine this species’ size histogram; what conclusion can you draw about whether it is invading or dropping out of this community? Is there anything about this species’ natural history (information available from the species windows) that might support why this species has such high density?
Assignment 2 – Distance-sampling Versus Area-sampling Methods – this assignment investigates distance sampling and compares it to area sampling, which you used in assignment 1. There are a number of so-called plot-less sampling techniques, including the random-pairs and point-quarter techniques, that utilize measurements of distances between individuals, or measurements of distances from randomly or systematically chosen points to the nearest individuals, instead of sampling within prescribed quadrats. We will use the point-quarter technique because it is easier and more efficient. This technique is well suited for sampling communities with widely spaced individuals or communities in which individuals are large in size (e.g., trees). The technique is easily adapted to sample animal populations such as nest densities (e.g., wood rat nests) or populations of sessile or sedentary animals (e.g., sea anemones and barnacles).
- Click on ‘Use another sampling technique with this community ’ to continue working with the ‘Mohn Mill Natural Area.’ This time chose systematic sampling under ‘Distance’ so that sampling points within the community can be located systematically. At each selected point, four quarters (i.e., northeast, northwest, southwest, and southeast) are created using a theoretical north-south line and a theoretical east-west line (this would be done with a compass in the field). Within each quarter, the tree nearest to the point is selected and its species identity, its point-to-plant distance, and its basal area are recorded. We then move to the next systematically chosen point and sample another set of four individuals.
- The number of points to sample in order to generate reliable abundance estimates is determined semi-objectively with use of the species-number of points curve in a manner identical to the species-area curve in area sampling. Once you are satisfied with your sampling, perform the calculations and save a copy for comparison to assignment 1 results.
Questions to Discuss in Your Write Up of Assignment 2
- Why might an investigator prefer distance sampling over area sampling (consider the ‘estimates of time commitment’ for area versus distance sampling)? Hint: think of what each method requires under the field conditions.
- Why might an investigator prefer area sampling over distance sampling? Hint: look at how density is calculated for each technique.
- Compare the abundance estimates that you calculated using the point-quarter method with those from the area method in assignment 1 (use the systematically collected samples for both methods). Are the density, dominance, and frequency values similar for common species with both methods? Are the density, dominance, and frequency values similar for rare species with both methods? Does species richness differ between the two methods, if so, how?
- Consider the importance values for the species you sampled. Find two species that have relatively high but similar importance values and compare their density, dominance, and frequency values. How similar or dissimilar are these values? Theoretically, is it possible that two species could have the same importance value but have very different values for density, dominance, and frequency, if so, how?
Assignment 3 – Dispersion and Succession –Density, dominance, and frequency can give an incomplete picture of how a population is distributed within a habitat. For example, the populations of two co-occurring species may have similar densities and comparable dominances but they may have quite different spatial-occurrence patterns. One population may be distributed relatively randomly while the other may be highly aggregated (clumped) within one portion of the site – perhaps in that portion of the habitat with high water availability. The arrangement of the individuals composing a population is referred to as ‘dispersion’ (not to be confused with dispersal, which is the movement of organisms or their propagules from one place to another). Knowledge of dispersion is useful because the aggregation of individuals may have greater impact on the species interactions than the average number of individuals per unit area.
There are several calculation methods for dispersion but we will use the Morisita Index of Dispersion for our estimates (Morisita 1959, Brower et al. 1998, see Appendix). If the dispersion is random, then the Morisita Index is approximately 1.0; if perfectly uniform, the Morisita Index approximates 0; and if maximally aggregated (i.e., all individuals in one plot), the Morisita Index = the number of quadrats or points sampled. The distribution of organisms in nature is seldom uniform as in an orchard or a cornfield. Instead, the dispersion of organisms is frequently aggregated. A random dispersion (one in which the position of an individual is completely independent of the position of any other individual in its population) can be approached in some species.
Succession refers to the replacement of one community by another and biologists contrast two types: (1) primary succession, which describes development starting from a new site never before colonized by living organisms and (2) secondary succession, which applies to the plant succession that takes place on sites that have already supported life. In a forest, secondary succession occurs each time a canopy tree falls and new plants compete for the resources (i.e., light, nutrients) previously used by the fallen tree. Secondary succession can also be observed after logging or when an agricultural field is fallowed.
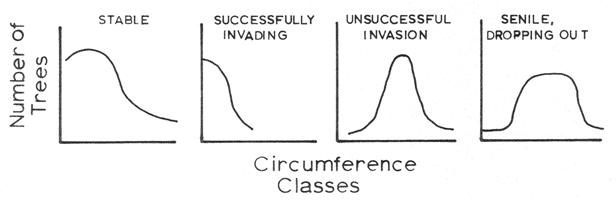
Although tree sizes do not precisely represent tree ages, tree-size data can provide insight into the successional status of tree species. The following graphic models illustrate the expected size-class distributions for hypothetical species with stable, successfully invading, unsuccessfully invading, and senile size-class structures. Actual size-class data are compared to these expectations to understand the history and to predict future success or failure of species in a given forest stand.
- For assignment 3, refer to the saved results that you obtained under assignment 1 for the ‘Mohn
Mill Natural Area’ using random sampling of quadrats. You do NOT need to rerun the sampling for the following questions rather refer to your saved output.
Questions to Discuss in Your Write Up of Assignment 3
- Identify the Morisita index for each sampled species in the calculated output. Which species has the lowest Morisita index? Does the dispersion index for this species suggest a uniform distribution – do you think this estimate is reliable, why or why not? Which, if any, species has a Morisita index approximating 1.0 – what does this suggest about its dispersion? Which species have the highest Morisita indices and what do these indices suggest about the distributions of these species within the sampled habitat?
- Compare the Morisita index with the frequency value for species with lower Morisita indices, for species with a Morisita index nearest 1.0, and for species with higher Morisita indices. Do these two measures follow the same general pattern? What does a low frequency compared to a high frequency suggest about the species distribution?
- Compare the size-distribution histogram of red maple with those of oaks (e.g., white oak, chestnut oak, and red/black oak). Which of the graphic models illustrated above match best with red maple and which model best fits the oaks?
- Given the size-distribution of red maple versus oaks, what prediction can you offer about the succession of species occurring at Mohn Mill?
Assignment 4 – Species Diversity –While dispersion is a characteristic of populations, species diversity is a characteristic unique to the community level of biological organization and is an expression of community structure. For example, a community has high species diversity if it is composed of many equally abundant species. On the other hand, if a community is composed of a very few species, or if only a few species are abundant, then that community’s species diversity is low. High species diversity potentially indicates a complex community because a greater variety of species likely facilitates more interactions among species. Species interactions involving energy transfer (food webs), predation, competition, and niche partitioning are theoretically more varied in a community of high species diversity. There are many estimates of species diversity but we will use the popular Shannon-Wiener Index to estimate species diversity in our virtual forests.
- Go to ‘Configuration options’ near the bottom of the ‘select a forest’ window. Set ‘Random quadrat list as links’ to yes and close this window. Next, select the ‘Snyder-Middleswarth Natural Area.’ Click on ‘description’ to obtain background information. Use random or systematic under ‘Area’ so that sample quadrats within the community can be located by random design.
- Near the upper right corner of the ‘community view’ window, you will see ‘Topographical View’ under ‘Community View’ – click on this link to see a three-dimensional topographic image of Swift Run’s valley. Note the locations of the southern ridge top (Thick Mountain), the north-facing slope, the Swift Run bottom lands, the south-facing slope, and northern ridge top (Buck Mountain).
- In the upper right corner of the ‘community view’ window, you will notice an option ‘Generate a random list of 50 quadrats.’ Click ‘Go.’ Click on each pair of the X, Y coordinates provided and sample the quadrat as you did before.
- Continue until you believe that you have a reliable estimate of the actual values – you can add additional X, Y coordinates if necessary.
- Perform the calculations and save a copy.
Question to Discuss in Your Write Up of Assignment 4
- Identify the Shannon-Wiener index for the Snyder-Middleswarth Natural Area. Compare this value to the Shannon-Wiener index for the Mohn Mill Natural Area from previously saved output. Which is higher and what does this suggest about the interactions within each of the two communities? Explain why the Shannon-Wiener index differed in the two communities. Hint: the Shannon-Wiener index has two components – species richness and evenness. As species richness increases, the species diversity of a community will also tend to increase. Similarly, greater evenness also increases species diversity.
- Compare the size-class distributions for hemlock and yellow birch within Snyder-Middleswarth old-growth forest to the theoretical expectations illustrated above. What conclusions can you make about the successional status of these species? Is there anything about the natural history of hemlock or yellow birch (information available from the species windows) that might support why these species have the size-class distributions they do? How might acid precipitation or hemlock wooly adelgids influence species abundances and succession?
- Compare the size-class distributions for sweet birch within Snyder-Middleswarth old-growth forest to the theoretical expectations illustrated above. What conclusions can you make about the successional status of sweet birch? Is there anything about sweet birch’s natural history (information available from the species windows) that might support why this species has the size-class distribution it does?
Assignment 5 – Variation in Patterns due to Topography and Edaphic Factors – This assignment investigates the variation in vegetative patterns due to topography and edaphic factors. There can be marked differences between adjacent north-facing and south-facing slopes. South-facing slopes in the northern hemisphere receive more solar radiation than north-facing slopes. At the latitude of Pennsylvania, midday insolation on a 20º slope is, on average, 40% greater on a south-facing slope than on a north-facing slope year-round. This difference has a striking effect on heat budget and moisture of the two sites – south-facing slopes are warmer, their evaporation rate is typically 50% higher, and their soil moisture is lower (Smith and Smith 2001). Contrast the vegetation that occurs on the south-facing and north-facing slopes; and compare the vegetation that dominates the Swift Run bottom land with that on the ridge top.
- We will use the ‘Snyder-Middleswarth Natural Area’ because of its dramatic topographic relief from the bottom land along Swift Run to the adjacent ridge tops. Select random or systematic under ‘Area’ so that sample quadrats within the community can be systematically sampled.
- The ‘Community View’ for this site is labeled to show the locations of five subsets of the old-growth forest: (1) southern ridge top (Thick Mountain), (2) north-facing slope, (3) bottom land forest along Swift Run, (4) south-facing slope, and (5) northern ridge top (Buck Mountain).
- In order to compare the vegetation of the bottom land and the ridge top, and the south-facing and north-facing slopes, systematically sample 30 quadrats within each of these portions of the forest. There are 150 quadrats that can be sampled in each subset area so sample every second quadrat and every second row. Begin sampling in the bottom land by sampling quadrat 110, 0 and then every second quadrat moving up the column (e.g., 110, 20; 110, 40; 110, 60; etc.) to the top of the column. Move two columns to the right (i.e., column 130) and sample quadrat 130, 290 and then every second quadrat moving down the column to its bottom. Continue until you have sampled at least 30 quadrats within the bottom land. Perform the calculations and click Finish.
- Apply the same procedure you used to sample the bottomland to the northern ridge top on Buck Mountain. Perform the calculations.
- Next, apply this procedure to the north-facing slope. Perform the calculations.
- Finally, apply this procedure to the south-facing slope. Perform the calculations and save a copy (be sure your output contains data from all four topographic areas).
Questions to Discuss in Your Write Up of Assignment 5
- Compare the species occurrences in the bottom land with those on the ridge top – describe how they differ. Is there anything about the natural history (information available from the species windows) of the two dominant species in each area that suggests why these species dominate in different parts of the Snyder-Middleswarth forest?
- Compare the species occurrences on the south-facing slope with those on the north-facing slope – describe how they differ. Is there anything about the natural histories (information available from the species windows) of the two most important species on each slope that suggests why these species dominate in different parts of the Snyder-Middleswarth forest?
- Describe the population structure of chestnut oak on the south-facing slope. Is there anything about this species’ natural history (information available from the species windows) that might support why this species has the density and frequency levels it does on the south-facing slope, while it is completely absent from the north-facing slope?
Sampling Theory Lab Reports
Your lab reports should include the answers to each of the 18 questions above. Do NOT include the saved output tables. Lab write-ups must be done individually, typed, single-spaced, and printed on both sides of the paper (please help conserve our forest resources). Reports are due in lab next week.
Literature Cited
Abrahamson, W. G. and A. C. Gohn. 2004. Classification and successional changes on mixed-oak forests at the Mohn Mill Area,
Pennsylvania. Castanea 69: 194-206. Click here for a pdf of this article.
Abrams, M. D. and C. M. Ruffner. 1995. Physiographic analysis of witness-tree distribution (1765-1798) and present forest cover through north central Pennsylvania. Canadian Journal of Forest Research 25: 659-668.
Barbour, M. G., J. H. Burk, W. D. Pitts, F. S. Gilliam, and M. W. Schwartz. 1999. Terrestrial plant ecology, 3rd edition. Benjamin Cummings.
Brower, J. E., J. H. Zar, and C. N. von Ende. 1998. Field and laboratory methods for general ecology, 4th edition. Wm. C. Brown Co., Publishers,
Dubuque,
Iowa.
Curtis, J. T. and G. Cottam. 1962. Plant ecology workbook: laboratory, field and reference manual. Burgess Publishing Company,
Minneapolis.
Morisita, M. 1959. Measuring the dispersion of individuals and analysis of the distributional patterns. Mem. Fac. Sci. Kyushu Univ., Ser E (Biol.) 2: 215-.
Smith, R. L. and T. M. Smith. 2001. Ecology and field biology, 6th edition. Benjamin Cummings.
Zawadzkas, P. P. and W. G. Abrahamson. 2003. Composition and tree-size distributions of the
Snyder-Middleswarth
Old-Growth
Forest,
Snyder County,
Pennsylvania. Castanea 68: 31-42. Click here for a pdf of this article.
Acknowledgments
We thank Steve Jordan and Matt McTammany for their insightful comments and suggestions throughout the development of EcoSampler. This exercise was stimulated by the methods exercises in Curtis and Cottam's Plant Ecology Workbook (1962).
Contacts for Problems or Questions
Warren G. Abrahamson abrahmsn@bucknell.edu; http://www.facstaff.bucknell.edu/abrahmsn/
Mike R. Weaver mweaver@bucknell.edu
Definitions of Abundance Measures
Area Method: (Brower et al. 1998)
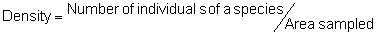
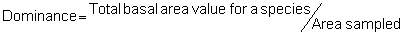
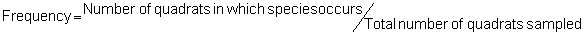
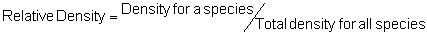
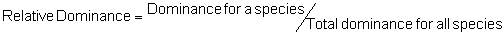
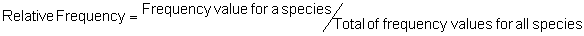
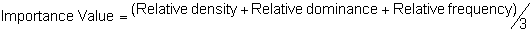
Point-quarter Method:
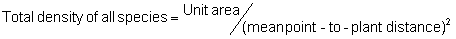
In the formula, the term ‘unit area’ refers to the size of the area, in the same units as those for the mean area per plant, on the basis of which density will be expressed. For example, if density is to be expressed per hectare, but the mean area per plant is in units of m2, the unit area value would be 10,000 (the number of m2 in a hectare).
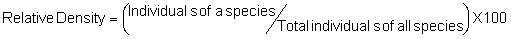
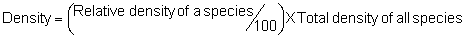
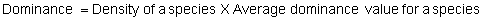 \
\
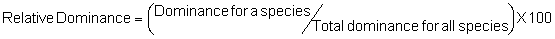
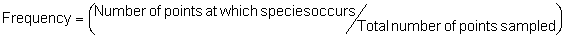
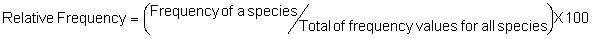
Definitions of Species Diversity and Dispersion (Brower et al. 1998)
Shannon-Wiener Index (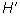 )
)
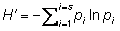
Where: 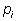 is the number of individuals of one species divided by the total number of all individuals in the sample (=ni/N), ln = natural logarithm, and s = total number of species in the community.
is the number of individuals of one species divided by the total number of all individuals in the sample (=ni/N), ln = natural logarithm, and s = total number of species in the community.
Morisita’s Index of Dispersion (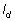 )
)
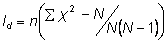
Where: 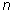 is the number of quadrats,
is the number of quadrats, 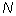 is the total number of individuals counted in all quadrats, and
is the total number of individuals counted in all quadrats, and 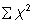 is the squares of the numbers of individuals per quadrat, summed over all quadrats.
is the squares of the numbers of individuals per quadrat, summed over all quadrats.